Summary: In this article, AI Scientist Ramin Fahimi describes the development and thinking behind Qii.AI’s Interactive Segmentation Tool and explains the challenges and obstacles the team faced from an AI perspective.
Introduction
In a recent blog post, my teammate Ashley discussed the role drones could be played as one of the best tools for extensive industrial asset inspections by collecting high-quality visual data that facilitates detailed visual inspections. But in addition to high-quality data, to make the most of the data also requires the ability to effectively, quickly, and accurately measure and annotate the information so that decisions can be made. If done manually, the process of annotating and highlighting specific anomalies is time-consuming and expensive – without assistance from the software, something as seemingly simple as annotating a crack boundary would be challenging and slow. That is why we applied computer vision and state-of-the-art machine learning technologies in Qii.AI to build a smart Interactive Segmentation Tool that facilitates quick annotation and prepares an accurate semantic mask, highlighting the area of interest or an object. In pursuit of this goal, we explored different types of interactive algorithms and looked for the best way to efficiently take inputs from users to “educate” the AI about our users’ needs.
We considered a variety of ways to accomplish this and finally found that using clicks as input is the fastest way to incorporate users’ inputs efficiently and effectively. Knowing that annotations must be complete and detailed and the fact that it is not acceptable to miss a critical anomaly, we built this algorithm in a way that it first identifies the salient defect or anomaly within a specific region of interest and then iteratively takes inputs from the user to refine the annotation in order to end up with the most accurate output, simultaneously making the inspector’s job much easier and making the AI better at predicting the boundaries of the anomalies in the first place.
To build the Interactive Segmentation tool, we started with large, diverse datasets, training a neural network that has the capability to annotate and segment almost any shape with a specialized ability to focus on and recognize industrial anomalies like corrosion, rust, coating breakdown, and cracks. This approach has worked well in our platform, and we have observed significant improvement in users’ experiences, using Qii.AI to annotate data and create reports.
As part of our programming mission, we are constantly looking for ways to improve our platform and make visual inspection even faster and more accurate. We measure our success based on the number of clicks required to annotate each anomaly, and we are constantly working to minimize this number. So far, based on user feedback, we’ve identified two characteristics of inspection datasets that present opportunities for the AI, namely that certain types of anomalies are usually repetitive in a single image and also across the dataset as a whole. This brings up questions of how we can train the AI to learn from a particular instance of an anomaly in an image, making it faster to annotate other instances of similar anomalies within the same image, as well as how to find a way to propagate that learned knowledge to apply to subsequent images while simultaneously learning from its human partner about un-recognized anomalies. We understand from our users that visual inspections often involve subjective judgments, so we believe that creating a personalized AI-user collaboration experience has immense value.

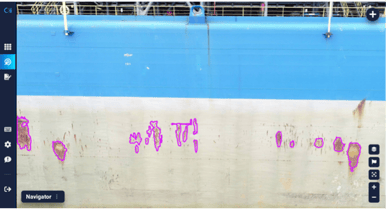
Figure 1) Repetitive anomalies are time-consuming to annotate, and we’d like to lower a number of clicks for similar anomalies within the same image and across other images in the dataset.
What is our proposed solution?
Humans easily acquire new skills and transfer knowledge across domains, but it is not so easy for machine learning algorithms. There are quite a few challenges:
- Resistance to “catastrophic forgetting”: newly learned knowledge from data should not destroy the knowledge developed from previously analyzed data; To overcome catastrophic forgetting, learning systems must, on the one hand, show the ability to acquire new knowledge and refine existing knowledge based on the continuous input of data and on the other hand, prevent the novel input from significantly interfering with existing knowledge.
- An important restriction of deep learning is the dependence on the quality of the data sets; a clean and well-built dataset is a critical pre-condition to an effective learning process, but user-inputs are not necessarily “noise-free”, so the algorithm should have noise tolerance and the ability to learn from noisy inputs.
- The algorithm must also be fast-to-learn, even with a small number of samples, in order to quickly return benefits to the user. This also requires blazing fast infrastructure and engineering work to be done.
- Learning should occur at every moment, with no fixed tasks or data sets and no clear boundaries between tasks. It should effectively learn from unordered data and unbalanced datasets where certain types of annotation and anomalies happen more frequently.
- The algorithm should learn the task and generalize over the concept rather than memorizing already seen instances of anomalies.
- Finally, the algorithm should deal with label sparsity. Our model was initially trained with full supervision, where we had accurate masks and labels created for each anomaly, and the algorithm had seen all of them and had learned strong shape priors. Now, the inputs are only clicks and not detailed masks.
We have been working on taking advantage of Continual Learning (CL) algorithms and applying it to interactive segmentation. The general idea behind continual learning is to make algorithms able to learn from a real-life data source. In a natural environment, the learning opportunities are not simultaneously available and need to be processed sequentially. Learning from the present data and continuing later with new data rather than learning only once looks appropriate in this application. So far, we are thrilled with our progress with CL, and we are hoping to make this service available to our users soon. Soon, every click that you earn while inspecting a project will save you time in the future, and it will help inspectors reach new levels of efficiency in creating detailed reports.